
Why MCP's Synchronous Model Breaks Creative Workflows (And What Comes Next)
Company Overview
Helmer
Timeline
2025
Model Context Protocol promised distribution without platform lock-in. Write your capabilities once, wrap them in a standard interface, and they work everywhere. Claude, ChatGPT, etc etc.
For simple tools, this works. For complex creative workflows, it doesn't
The debate right now is whether MCP becomes infrastructure for the next generation of software, or whether it gets relegated to 'works great for deterministic tasks, doesn't scale for anything real'.
We think the answer is neither. The interesting path is agents as MCP - where the server itself has autonomy, and synchronous interfaces become wrappers around asynchronous intelligence. At Helmer, we hit MCP's architectural limits hard enough that we're rebuilding around this pattern entirely.
The service trap that exposed the problem
February 2025. Sid and I launched Batchwork by Helmer with a specific thesis: AI media generation had gotten good enough and fast enough that you could take structured databases and turn them into thousands of personalized assets. Product catalogs where each item gets a unique media. Real estate listings where every property gets promotional content optimized for it.
The technology worked. We could generate thousands of on-brand media from structured data. Colors, fonts, tone, etc all locked in and consistent. Started working with clients like tickadoo, turning their experience databases into media assets at scale.
But here's the thing with service based offering - every client needed us directly involved. We'd be in their Slack channels daily, reviewing outputs, adjusting parameters, shepherding projects through. It was consulting work disguised as a software product. Which neither of was wanted to do.
Our technology could serve 100 clients easily. But if we had to be directly involved in each one them, we could maybe take on 3 before we'd collapse.
This is the classic "doing things that don't scale" problem, except the thing that doesn't scale is the entire business model. So we had to ask ourselves "how do we get our capabilities into people's hands without being in the loop at all?"
MCP seemed like the answer.
Why MCP Seemed Perfect
MCP's promise is self-service distribution. Build once, expose everywhere, meet users where they work. For deterministic operations that finish in seconds, this is the right model. It's why MCP took off for database queries, file operations, and API calls, etc. Basically tasks with clear inputs, predictable execution, fast completion.
We built Helmer's MCP server and exposed tools for branded media generation: static images, social posts, short videos, voiceovers (thanks to Eleven Labs grant). Here's an example of an Instagram series we generated that's completely on-brand.
What we found:
Some operations were perfect for MCP - fast, deterministic, finished in seconds
Other complex tasks hit a wall - they needed minutes, not seconds, and constantly timed out
What actually happens:
User asks Claude to create something complex
Claude calls Helmer's tool
30 seconds pass
Client times out and disconnects
Helmer keeps working in isolation
LLM keeps waiting
No result
Patience is a virtue, but MCP disagrees.
Forcing creative workflows into a synchronous execution model that assumes all work completes in one shot doesn’t work.
What MCP doesn't capture
The timeout wall is obvious. Less obvious are the four structural gaps that make MCP unworkable for complex creative execution.
Creative work requires iteration, not single-shot execution
MCP is request-response only. Any error and the whole thing dies. That's not how creative work actually happens. You need to retry specific pieces without starting everything over.
This is the distinction that matters: deterministic work can fail atomically. Creative work fails at multiple stages (generation, quality checking, brand validation, format conversion), and recovery means isolating failures and retrying specific steps. Synchronous tools can't do this because they don't persist intermediate state.
Quality work takes however long it takes
Some work legitimately needs time. Not because the infrastructure is slow, but because iteration and quality checking can't be rushed. Rome wasn't built in 60 seconds.
Trying to force unbounded creative work into 60-second timeouts just doesn't work. You can optimize execution all you want, but thoughtful work takes whatever time it requires.
MCP's model assumes bounded execution time. That assumption works for API calls and database queries. It breaks for workflows where ‘done’ means ‘meets quality bar’.
What about questions?
Agents ask questions for clarity. Even mid-project. If you use Claude or GPT, you know it asks questions even in the middle of ongoing work. But MCP is built for request → response. There's no way to say "pause for a sec, I need to ask something, then I'll keep going."
Synchronous tools don't have a model for pausing execution to gather human input, because the connection holding the execution context alive doesn't persist long enough.
Multi-session context that spans days
Actual work doesn't happen in one sitting. Especially thoughtful, tasteful media, which is the standard Helmer needs to maintain.
The system needs to remember everything: what decisions got made and why, what approaches were tried, what the user said they wanted, brand guidelines, quality standards.
Our MCP tools are stateless by design. Close your browser and poof …. context gone.
This is where MCP inherits a limitation from its parent protocols. HTTP is stateless. APIs are stateless. MCP tools are stateless. That's fine for operations that complete in one call. It's unworkable for projects that span days and require accumulated context to maintain quality and consistency.
Why "just add memory" doesn't solve this
The obvious fix is persistence. Add memory to MCP, preserve context across calls, resume where you left off.
This addresses state management. It doesn't address autonomy.
Complex creative tasks fail because:
Failure modes that multiply. In synchronous tools, any failure is fatal. The entire execution dies, user gets an error, start over. Creative work has failure modes at multiple stages. A system that can't isolate and retry specific failures can't handle creative workflows.
Recovery that requires intelligence. When something doesn't work, the system needs to adapt and try different approaches, adjust parameters, iterate on quality. These aren't predefined branches you can hardcode. Recovery requires judgment: "this approach isn't working, let me try another angle." Synchronous tools don't have agency between calls.
Conversations that span sessions. A project starts Monday. User provides feedback Tuesday. Reviews draft Wednesday. The system needs to remember not just data, but context.
Memory helps with the third issue. It does nothing for the first two. You still timeout on long work. You still can't pause mid-execution to ask clarifying questions. The intelligence is still stuck at the tool level.
Adding memory means database writes on every tool call, storage costs piling up, and human-in-the-loop interactions that remain fundamentally awkward. It's like putting a band-aid on a broken bone. Sure, there's something there now, but it's not addressing what's actually broken.
Can we make give the timeouts a little more room?
Sure. But does it solve the core problem. No.
Making timeouts longer doesn't solve the architectural mismatch. Even with 5-minute timeouts, you still have:
Fatal failure modes that can't isolate and retry
No mid-execution human-in-the-loop
No genuine iteration based on quality judgment
Context that dies when the connection drops
The fundamental trade-off remains: either the orchestrating LLM owns intelligence (and hits capability limits because it can't see inside execution), or the MCP server owns intelligence (and needs autonomy that breaks synchronicity).
Anthropic and OpenAI want MCP to work for thousands of tools across every domain. That means the protocol needs to be simple, standardized, and work for the common case. The common case is deterministic operations with bounded execution time. MCP are optimized for breadth and not depth.
We tried to make it work but some things are just not meant to be
Our agent was too big for MCP's box. So why not just build our own platform exactly how we want it?
We did our own platform. It looked cute.
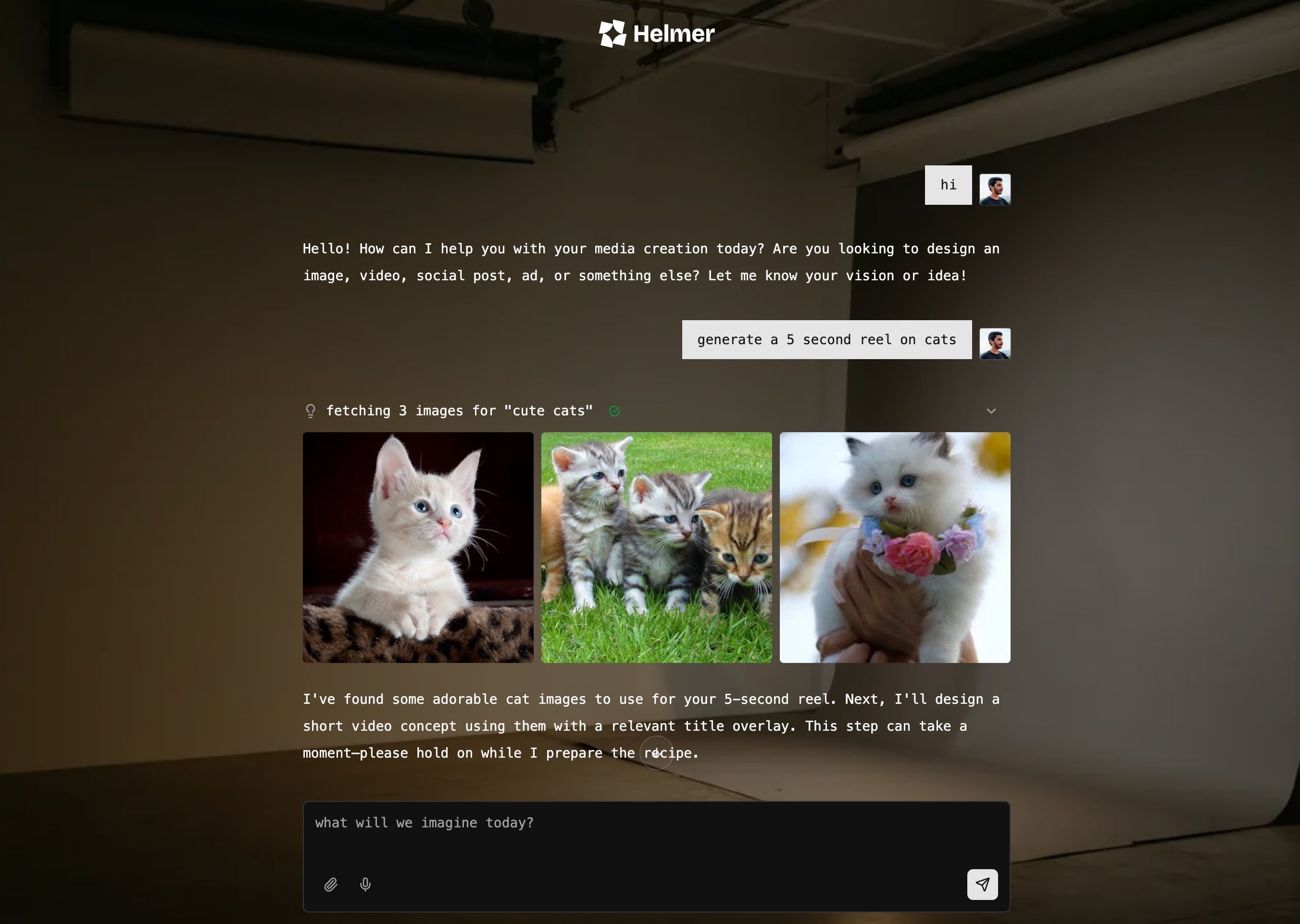
But from a distribution standpoint, we'd be right back where we started. Another platform people need to come to, learn, integrate with, remember to check. The whole point was meeting people where they already work. Building our own platform is just giving up on that.
Then we thought, what if agents is the serve? Maybe we can expose agents as MCPs itself. Not "what if we make our tools fit MCP" but "what if we wrap an autonomous agent in MCP's interface?"
An autonomus agent that can:
Internal LLM makes decisions
Uses Helmer's internal capabilities
Iterates until quality meets requirements
Pauses to ask for human input when genuinely uncertain
Resumes exactly where it left off
Geniunen autonomy and intelligence. MCP stays synchronous. The agent stays autonomous. The wrapper makes them compatible.
We know this will come with new set of issues, for example. A few I think of right now:
Someone Else's Money vs Our Money
In our current state, user's Claude subscription pays for LLM calls. We just provide infrastructure. If we take the agent-as-MCP route, We pay for every LLM call the agent makes. The agent might make dozens or even hundreds of LLM calls per project. Each one costs us money. So how do we price this without either:
Overcharging (scaring users away)
Undercharging (going bankrupt)
Making costs unpredictable (destroying trust)
Teaching the agent to say NO!
If Helmer is running an autonomous agent we're paying for, we need to prevent misuse. "Build me a todo app in React" should fail, not burn budget. But enforcing "media-related tasks only" means walking a line between being too restrictive (rejecting legitimate creative requests) and too permissive (burning money on off-topic work).
You can't just pattern-match keywords. Creative requests are open-ended by nature. The agent needs genuine understanding of task scope, not just input filterin
Memory is expensive.
An agent working across multiple days needs to remember:
Everything it's tried
What worked, what didn't
User's preferences and feedback
Brand guidelines
Current progress
Why it made certain decisions
An agent working across multiple days needs to remember everything it's tried, what worked, what didn't, user preferences, brand guidelines, current progress, why it made certain decisions. Every state change is a database write. Every status check is a read. At scale, storage costs compound fast.
The naive approach is to persist everything, which is expensive. The other extreme is to throw out most context which loses the continuity that makes multi-session work possible. There's a middle path, but finding it requires actual usage data.
An interesting observation I made while working on a side project with Claude code is that the decision traces that make autonomy possible. When the agent has a library of past projects, quality iterations, user feedback, and brand adjustments, it gets better at predicting what will work. The context compounds.
Where this leads: new systems of record
Over time, the decision traces these agents accumulate become more valuable than the outputs they generate.
Helmer agent will capture what approaches worked for which brands, what user feedback patterns emerged, which quality thresholds matter for different use cases. That accumulated context becomes a queryable library of precedents.
The decision traces that explain not just what happened, but why it was allowed to happen. Over time, they become the real source of truth for autonomy.
Will it work? We'll find out by shipping it. I will keep you updated.
If you're working on similar infrastructure or want to use Helmer, let's talk.
Liked what you see?
I'm actively exploring new opportunities in branding, marketing and content starting June 2025.